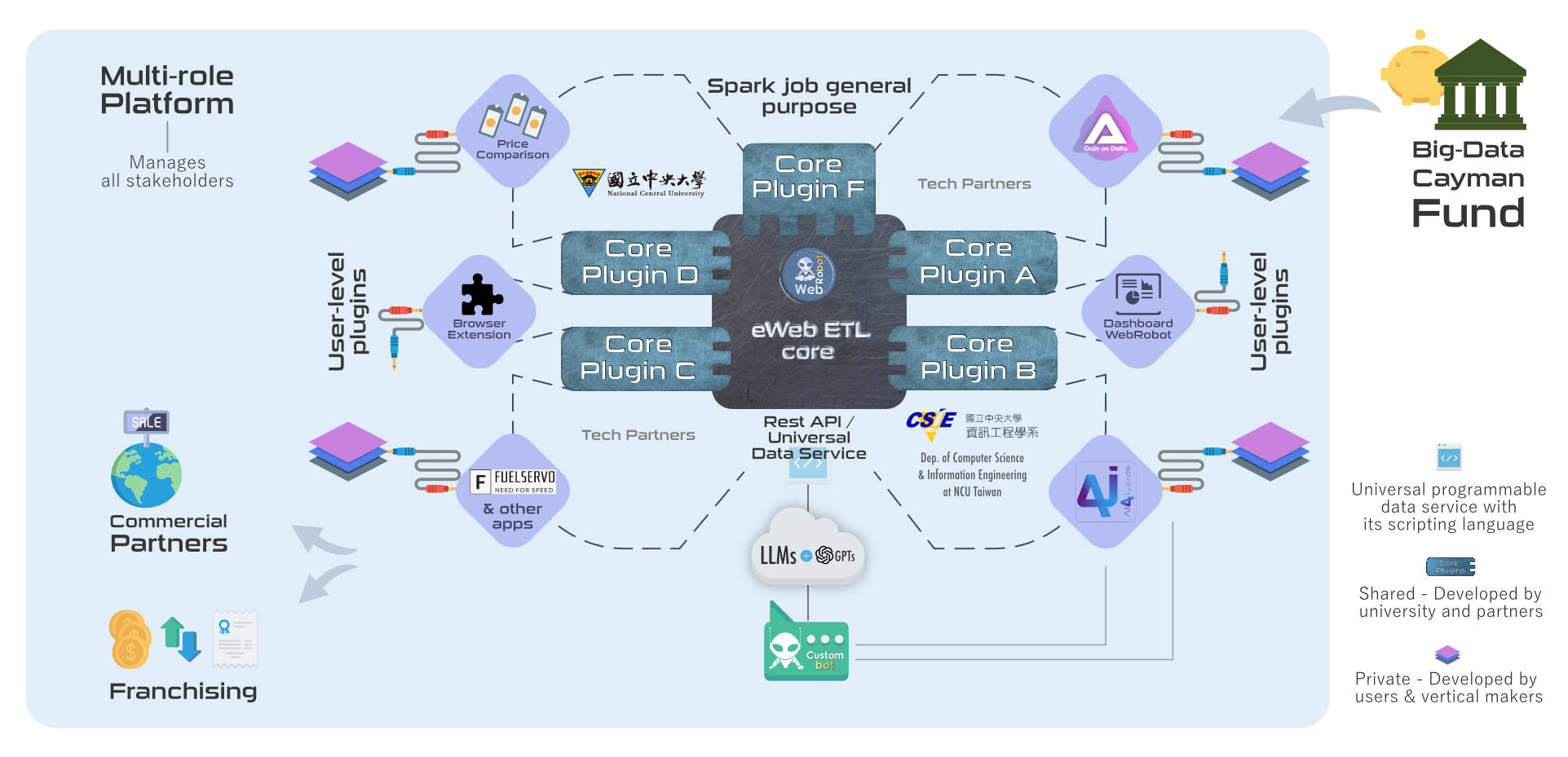
No-code Big-Data Web Scraping and Data Science Automation
Data extraction and management at your fingertips
Extract and manage millions of data points at scale in a few clicks and less time. Take your business and research to the top level with our data science automation and AI-powered no-code and low-code big-data web scraping service and tools.
Embrace technology democratisation through intuitive and user-friendly data extraction designed for users of all skill levels.
Get ready for a prompt-centred chatbot-based User Interface and a VUI for human-spoken interaction with our data infrastructure and services.
Become an early adopter and get exclusive offers. Join our waiting list.
Keep focused on your core business and save time and troubles thanks to our managed data extraction service. We do all the hard work while you enjoy the results.
Scrape the web and extract your data without knowing all the technical stuff. Tell us your needs and objectives and we design the best data extraction solution for you.
Would you like to pay just for what you need? Our plans are modulated based on the number of records and scrapers* (websites you need to extract the data from).
But whatever package you choose, we always offer the same top quality. We use our high-performance Spark-based big-data extraction engine to deliver the best datasets and results.
Every plan also includes:
Monthly⁵ or one-time duration
100%
Static and dynamic pages
100%
Plan cancellation at any time
100%
Upgrade always possible¹
100%
No minimum contract duration
100%
Compliant with GDPR and similar
100%
NEW
FROM
£150
Per Month
Number of pages: up to 10 Million (more on request)Number of websites (scrapers/extraction bots*): from 1 to 30 (more on request)Unlimited extraction projects³Unlimited URLs⁴
Datasets delivery frequency: daily, weekly, biweekly, monthlyOne-time setup cost: £168/website*Monthly maintenance: £63/websiteReady-made or custom extraction templates (bots/scrapers)
¹You can purchase new complete plans, additional records packs or additional scrapers (websites) packs to add to your current plan. Adding just records won’t charge you for any setup or maintenance costs (already included in the plans you already have). Adding new scrapers means you will be charged with additional setup and maintenance costs because we need to design new extraction queries and bots.
³ Within the number of pages and scrapers purchased.
⁴ Within the number of websites purchased. The exact number of URLs and web pages extract at the end of the month or project will depend on each project and the client’s specifications.
⁵ The subscription plans will auto-renew until you cancel it.
* Websites and pages have different structures and layouts. Furthermore, you may need to extract different data from some or every category/page. This requires designing and running different extraction bots (scrapers) for any of them. For example, when you want to extract data from Amazon, eBay, and Walmart, you need to design at least three different scrapers.
Note: All prices do not include VAT or other sales taxes. The Client is responsible for paying the sales tax/VAT when required by law. When the law will require WebRobot Ltd to charge for the sales tax/VAT, the Client will be informed during the purchase process.
Free Trial? Pay-per-use?
Custom or Unlimited Records?
Discover our big-data web scraping tool (special deal available)